Python, why and how it fits in Machine Learning
Python, why and how it fits in Machine Learning

Why Python
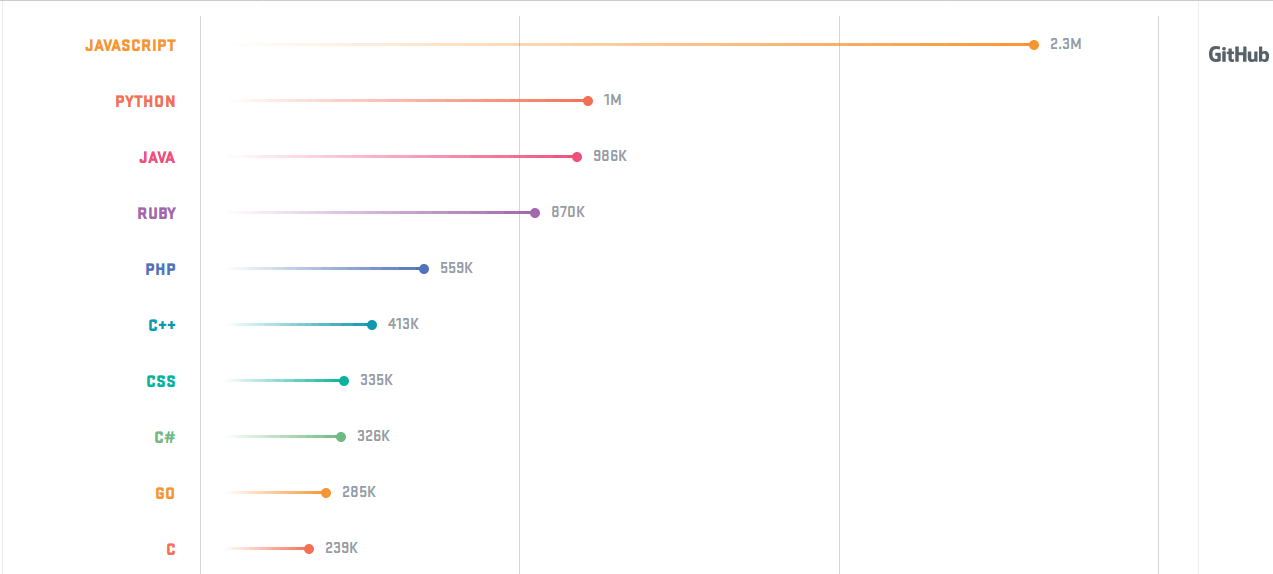
Python has grown rapidly in the last few years to become a very popular language. It is one of the official programming languages at Google, and the average Python developer salary in the U.S. is $116,043. Python replaced Java as the second-most popular language on GitHub, with 40 percent more pull requests opened in 2017 as compared to 2016.
I started to code by learning Java during my high-school, and it was not easy to grasp Java. I could not do anything much productive with Java initially. I started learning Python approximately 4 years back, I am still amazed how much could be done python with so much ease, reading python is equivalent (almost) to reading English. I will give you 4 reasons why you should learn python.
1. Python is easy
Python is very easy to learn, easier said than done right? Below are two codes, first is in Python and second is in C++ to calculate the number of occurrence of a word in a text file.
If you look at above codes it’s easily visible which of the above is easy to read and understand.
2.No need for details
After learning basics of python language you can directly start building cool things, without a need to understand in detail the working of everything, this is the most important reason to learn python, Python has tons of inbuilt libraries which makes doing many things in python very easy. BeautifulSoup, numPy, SciPy, OpenCV and much more prebuilt libraries makes life much more easier. The code below shows two screens using your webcam one is video output with coloured image and one black and white. The code below uses webcam to output two video screens, one is coloured and one is black & white. This can be achieved by using OpenCV in under 20 lines of code.

3.Python is iterative and agile
Developing a project is fast in python because you have to type less code and code structure is easy to write and understand.
When developing a project general build flow is :
- Build something
- Find flaw in it
- Improve it (or try to improve and pull your hairs out in the process) until you are satisfied.
Since writing code is easy and minimal code is required to do a task in python, so development is fast in python.Going from idea to implementation quickly is favoured in python and one of the reasons why you should learn python. Let me tell you a story (no no, not a long and boring one). In my University every student is given a login ID (which is our Enrollment no.) and a password to access WiFi with a fixed amount of data, and default password given is in a fixed pattern. One of my friends found that password patterns and brute forced all user IDs using python, and found the password of many IDs. It was easier for him to do this because by using urllib module he was able to easily implement his ideas with few lines of code. By the way, later University caught on to this and improved their security.
4.Python is the future of Machine Learning
Practically all of the most popular and widely used deep-learning frameworks are implemented in Python on the surface and C/C++ under the hood. The main reason is that Python is widely used in scientific and research communities, because it’s easy to experiment with new ideas and code prototypes quickly in a language with minimal syntax like Python. Python numerical computation engines such as NumPy and SciPy, allow complex calculations to be done by a single “import” statement followed by a function call. Speed isn’t a critical factor for python. Python is used for the logic and the performance critical parts are written Natively, having the advantages of both worlds. Given the flexibility of the language, its speed, and the machine learning functionality delivered by libraries such as scikit-learn, Keras, and TensorFlow, we’ll continue to see Python dominate the machine learning landscape.
Why should you pursue a career as a data scientist? Because average salary of a data scientist in USA is $120,931 with experienced persons earning much more and it has been regarded as one of the most sexiest job by Harvard Business School.
The basic program when starting to learn a programming language is “Hello World” program. So lets make a hello world project of machine learning. We will use iris data set for this project. We will do the classification of the iris data set, its like hello world of the machine learning, you can read about iris data set.
We will do this in 2 steps:
1. Installing and setting up system
I don’t want to waste much part on this system step, since this part is covered everywhere in detail, a simple google search is sufficient for this. Linux and Mac OS has python already been setup to install scipy, sklearn, pandas, numpy they can follow this and for windows user installing Anaconda would be easier.
2. Running the code
The iris data set contains five columns,they are sepal-length, sepal-width, petal-length, petal-width and class of the iris. The data set contains 50 entries for each the 3 class. We will first make a machine learning model and then check the accuracy our model. We will train our model using the popular SVM(Support Vector Machine) algorithm, to check the accuracy we divide our data set into two parts, one part serves as input for training the model and other test are run on the other part to check accuracy. So let’s get started.
In the first part of the code we are importing the necessary modules to be used in this project, like sklearn contains necessary functions to implement the SVM algorithm which we will use and other necessary functions, pandas is used to read text from .csv file.
In second part of program we are importing iris data set which is to be used.
In the third part of the program we are just printing 20 values from dataset to peek into our data.
In the fourth part we are randomly dividing our data into 75% for training and 25% for testing by setting validation_size as 0.25 and training our model using SVM classifier. The clf.fit(X_train, Y_train) is where actual training happens in the code. Then clf.score(X_validation,Y_validation) gives the accuracy by running X_validation and Y_validation values on the already trained model, since this data was divided randomly so we get a fair idea on approximate accuracy of our model, for this project, with this data set and classifier we get our output as “Accuracy is 0.973684210526” which means our accuracy is about 97.36%.
This is all from my side today, I hope you understood why python is used and it is growing in the field of Machine Learning. If you encounter any problem with the code or want to discuss something, please comment below. May the force be with you. Happy Learning :-)